Cost comparison: GitHub Actions Runner Controller (ARC) and WarpBuild
Comparing Cost Efficiency of GitHub Actions Runner Controller (ARC) using kubernetes and karpenter on AWS with WarpBuild BYOC runners. WarpBuild leads to >40% cost savings.

In this case study, we will explore the cost, flexibility, and management aspects of running your own GitHub Actions Runners using ARC (Actions Runner Controller) vs. using WarpBuild's Bring Your Own Cloud (BYOC) offering on AWS.
TL;DR
In this case study, we compare setting up GitHub's Action Runner Controller on EKS using Karpenter for autoscaling, with WarpBuild's BYOC offering. We found that ARC comes with significant operational overhead and efficiency challenges. On the other hand, WarpBuild's BYOC solution provides better performance, ease of use, and lower operational costs, making it a more suitable choice for teams, especially with large volumes of CI/CD workflows.
Cost Comparison Highlights:
The cost comparison is for a representative 2 hour period, where there is a continuous load of commits, each triggering a job. We use PostHog OSS as an example repo to demonstrate the cost comparison on real world use cases over 960 jobs.
- ARC Setup Cost (for the analyzed period): $42.60
- WarpBuild BYOC Cost: $25.20
This is effectively a ~41% cost savings.
 You can find the detailed cost comparison here.
You can find the detailed cost comparison here.
The following sections describe the setup of ARC Runners on EKS, and the assumptions that went into this.
Setting up ARC Runners on EKS
We setup Karpenter v1 and EKS using Terraform to provision the infrastructure. This approach provided more control, automation, and consistency in deploying and managing the EKS cluster and related resources.
Complete setup code is available @ https://github.com/WarpBuilds/github-arc-setup
EKS Cluster Setup
The EKS cluster was provisioned using Terraform and runs on Kubernetes v1.30.
A key aspect of our setup was using a dedicated node group for essential add-ons, keeping them isolated from other workloads. The default-ng node group utilizes t3.xlarge instance types, with taints to ensure that only critical workloads, such as Networking, DNS management, Node management, ARC controllers etc. can be scheduled on these nodes.
module "eks" {
source = "terraform-aws-modules/eks/aws"
cluster_name = local.cluster_name
cluster_version = "1.30"
cluster_endpoint_public_access = true
cluster_addons = {
coredns = {}
eks-pod-identity-agent = {}
kube-proxy = {}
vpc-cni = {}
}
subnet_ids = var.private_subnet_ids
vpc_id = var.vpc_id
eks_managed_node_groups = {
default-ng = {
desired_capacity = 2
max_capacity = 5
min_capacity = 1
instance_types = ["t3.xlarge"]
subnet_ids = var.private_subnet_ids
taints = {
addons = {
key = "CriticalAddonsOnly"
value = "true"
effect = "NO_SCHEDULE"
}
}
}
}
node_security_group_tags = merge(local.tags, {
"karpenter.sh/discovery" = local.cluster_name
})
enable_cluster_creator_admin_permissions = true
tags = local.tags
}Private Subnets and NAT Gateway
To secure our infrastructure, we placed the EKS nodes in private subnets, allowing them to communicate with external resources through a NAT Gateway. This configuration ensured that the nodes could still access the internet for essential tasks without exposing them directly to external traffic. Using private subnets with a NAT Gateway enhanced the security posture of the cluster while allowing for the necessary external connectivity.
Karpenter for Autoscaling
To manage autoscaling of the nodes and optimize cost and resource efficiency, we utilized Karpenter, which offers a more flexible and cost-effective alternative to the Kubernetes Cluster Autoscaler. Karpenter allows nodes to be created and terminated dynamically based on real-time resource needs, reducing over-provisioning and unnecessary costs.
We deployed Karpenter using Terraform and Helm, with some notable configurations:
- Karpenter v1.0.2: We chose the latest version of karpenter at the time of writing.
- Amazon Linux 2023 (AL2023): The default NodeClass provisions nodes with AL2023, and each node is configured with 300GiB of EBS storage. This additional storage is crucial for workloads that require high disk usage, such as CI/CD runners, preventing out-of-disk errors commonly encountered with default node storage (17GiB). This needs to be increased based on the number of jobs expected to run on a node in parallel.
- Private Subnet Selection: The NodeClass is configured to use the private subnets created earlier. This ensures that nodes are spun up in a secure, isolated environment, consistent with the EKS cluster's network setup.
- m7a Node Families: Using the NodePool resource, we restricted node provisioning to the m7a instance family. These instances were chosen for their performance-to-cost efficiency and are only provisioned in the us-east-1a and us-east-1b Availability Zones.
- On-demand Instances: While Karpenter supports Spot Instances for cost savings, we opted for on-demand instances for an equivalent cost comparison.
- Consolidation Policy: We configured a 5-minute consolidation delay, preventing premature node terminations that could disrupt workflows. Karpenter will only consolidate nodes once they are underutilized for at least 5 minutes, ensuring stable operations during peak workloads.
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
cluster_name = module.eks.cluster_name
enable_pod_identity = true
create_pod_identity_association = true
create_instance_profile = true
node_iam_role_additional_policies = {
AmazonSSMManagedInstanceCore = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}
tags = local.tags
}
resource "helm_release" "karpenter-crd" {
namespace = "karpenter"
create_namespace = true
name = "karpenter-crd"
repository = "oci://public.ecr.aws/karpenter"
chart = "karpenter-crd"
version = "1.0.2"
wait = true
values = []
}
resource "helm_release" "karpenter" {
depends_on = [helm_release.karpenter-crd]
namespace = "karpenter"
create_namespace = true
name = "karpenter"
repository = "oci://public.ecr.aws/karpenter"
chart = "karpenter"
version = "1.0.2"
wait = true
skip_crds = true
values = [
<<-EOT
serviceAccount:
name: ${module.karpenter.service_account}
settings:
clusterName: ${module.eks.cluster_name}
clusterEndpoint: ${module.eks.cluster_endpoint}
EOT
]
}
resource "kubectl_manifest" "karpenter_node_class" {
yaml_body = <<-YAML
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2023
detailedMonitoring: true
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 300Gi
volumeType: gp3
deleteOnTermination: true
iops: 5000
throughput: 500
instanceProfile: ${module.karpenter.instance_profile_name}
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: ${module.eks.cluster_name}
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: ${module.eks.cluster_name}
tags:
karpenter.sh/discovery: ${module.eks.cluster_name}
Project: arc-test-praj
YAML
depends_on = [
helm_release.karpenter,
helm_release.karpenter-crd
]
}
resource "kubectl_manifest" "karpenter_node_pool" {
yaml_body = <<-YAML
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
tags:
Project: arc-test-praj
nodeClassRef:
name: default
requirements:
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["m"]
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["m7a"]
- key: "karpenter.k8s.aws/instance-cpu"
operator: In
values: ["4", "8", "16", "32", "64"]
- key: "karpenter.k8s.aws/instance-generation"
operator: Gt
values: ["2"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-east-1a", "us-east-1b"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["on-demand"]
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 5m
YAML
depends_on = [
kubectl_manifest.karpenter_node_class
]
}We also ran another setup with a single job per node to compare the performance and cost implications of running multiple jobs on a single node.
- key: "karpenter.k8s.aws/instance-cpu"
- operator: In
- values: ["4", "8", "16", "32", "64"]
+ key: "karpenter.k8s.aws/instance-cpu"
+ operator: In
+ values: ["8"]Actions Runner Controller and Runner Scale Set
Once Karpenter was configured, we proceeded to set up the GitHub Actions Runner Controller (ARC) and the Runner Scale Set using Helm.
The ARC setup was deployed with Helm using the following command and values:
helm upgrade arc \
--namespace "${NAMESPACE}" \
oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set-controller \
--values runner-set-values.yaml --installtolerations:
- key: "CriticalAddonsOnly"
operator: "Equal"
value: "true"
effect: "NoSchedule"This configuration applies tolerations to the controller, enabling it to run on nodes with the CriticalAddonsOnly taint i.e. default-ng nodegroup, ensuring it doesn't interfere with other runner workloads.
Next, we set up the Runner Scale Set using another Helm command:
helm upgrade warp-praj-arc-test oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set --namespace ${NAMESPACE} --values values.yaml --installThe key points for our Runner Scale Set configuration:
- GitHub App Integration: We connected our runners to GitHub via a GitHub App, enabling the runners to operate at the organization level.\
- Listener Tolerations: Like the controller, the listener template also included tolerations to allow it to run on the
default-ngnode group. - Custom Image for Runners: We used a custom Docker image for the runner pods (detailed in the next section).
- Resource Requirements: To simulate high-performance runners, the runner pods were configured to require 8 CPU cores and 32 GiB of RAM, which aligns with the performance of an 8x runner used in the workflows.
githubConfigUrl: "https://github.com/Warpbuilds"
githubConfigSecret:
github_app_id: "<APP_ID>"
github_app_installation_id: "<APP_INSTALLATION_ID>"
github_app_private_key: |
-----BEGIN RSA PRIVATE KEY-----
[your-private-key-contents]
-----END RSA PRIVATE KEY-----
github_token: ""
listenerTemplate:
spec:
containers:
- name: listener
securityContext:
runAsUser: 1000
tolerations:
- key: "CriticalAddonsOnly"
operator: "Equal"
value: "true"
effect: "NoSchedule"
template:
spec:
containers:
- name: runner
image: <public_ecr_image_url>
command: ["/home/runner/run.sh"]
resources:
requests:
cpu: "4"
memory: "16Gi"
limits:
cpu: "8"
memory: "32Gi"
controllerServiceAccount:
namespace: arc-systems
name: arc-gha-rs-controllerCustom Image for Runner Pods
By default, the Runner Scale Sets use GitHub's official actions-runner image. However, this image doesn't include essential utilities such as wget, curl, and git, which are required by various workflows.
To address this, we created a custom Docker image based on GitHub's runner image, adding the necessary tools. This image was hosted in a public ECR repository and was used by the runner pods during our tests. The custom image allowed us to run workflows without missing dependencies and ensured smooth execution.
FROM ghcr.io/actions/actions-runner:2.319.1
RUN sudo apt-get update && sudo apt-get install -y wget curl unzip git
RUN sudo apt-get clean && sudo rm -rf /var/lib/apt/lists/*This approach ensured that our runners were always equipped with the required utilities, preventing errors and reducing friction during the workflow runs.
Tagging Infrastructure for Cost Tracking
In order to track costs effectively during the ARC setup, we implemented cost allocation tags across all the resources that we used for the setup along with collecting hourly data. AWS Cost Explorer allowed us to monitor and attribute costs to specific resources based on these tags. This was essential for calculating the true cost of running ARC compared to the WarpBuild BYOC solution.
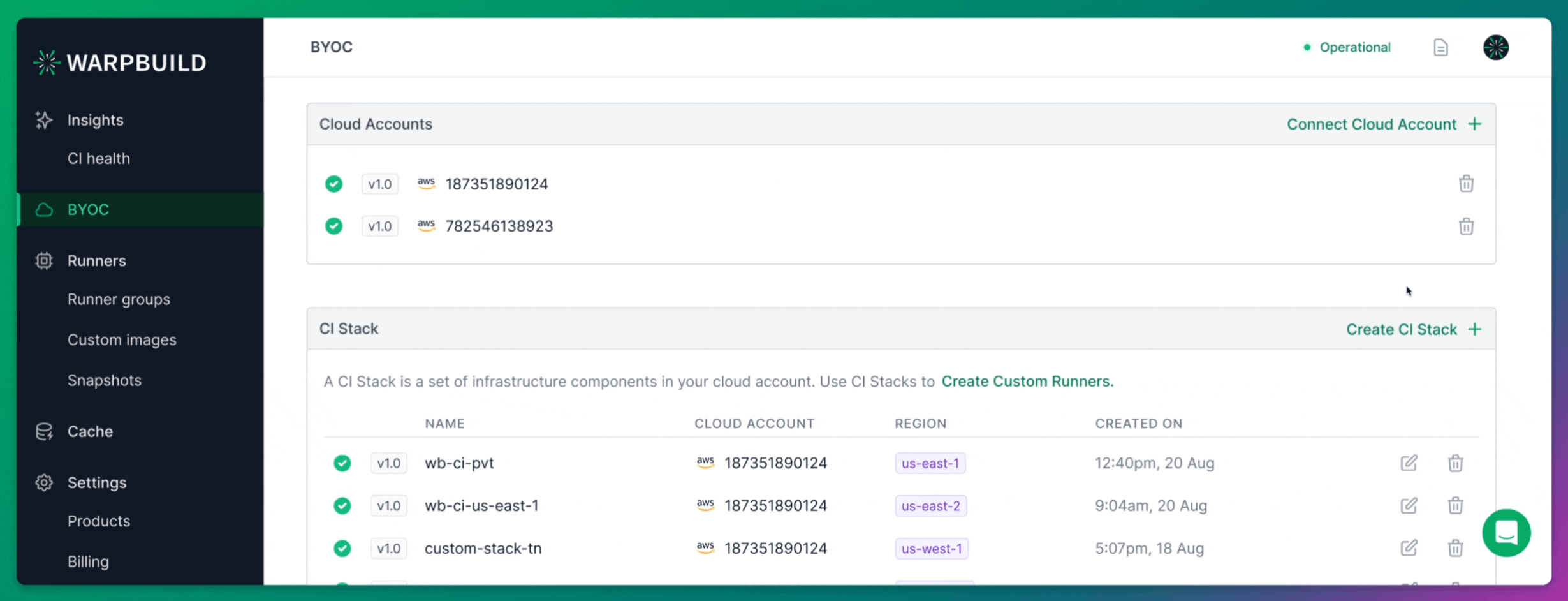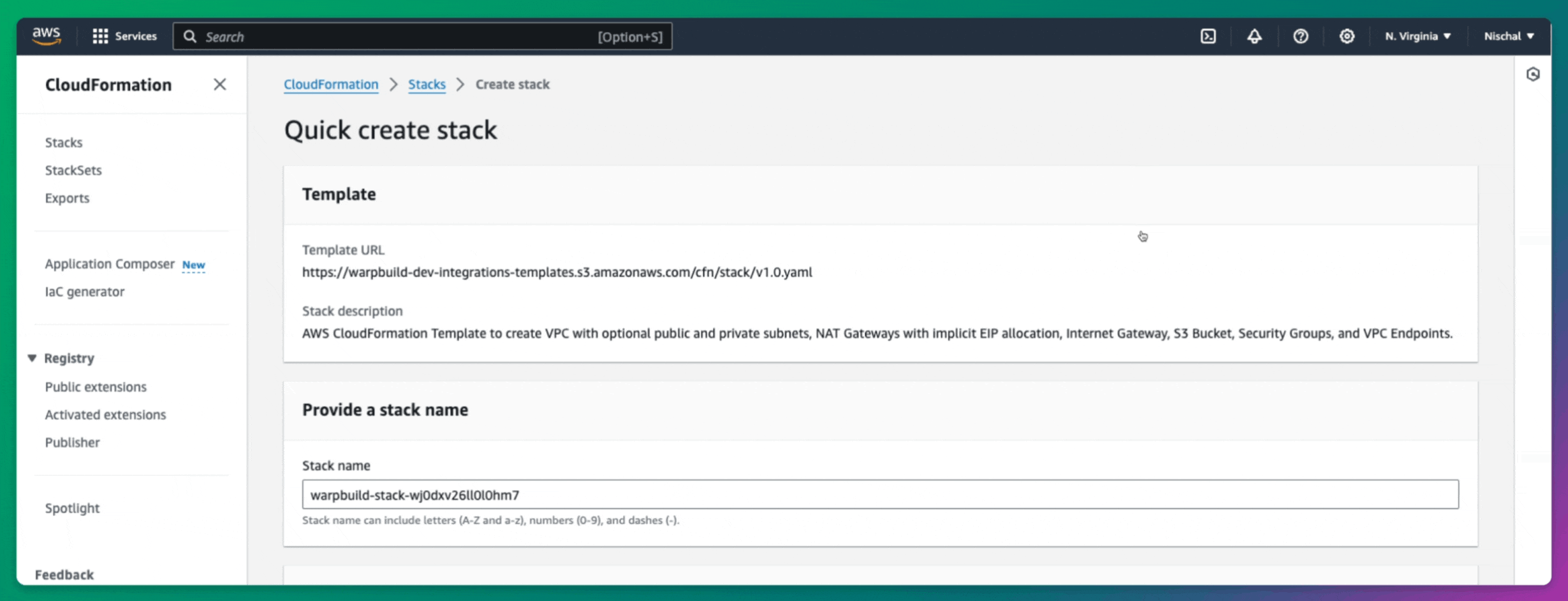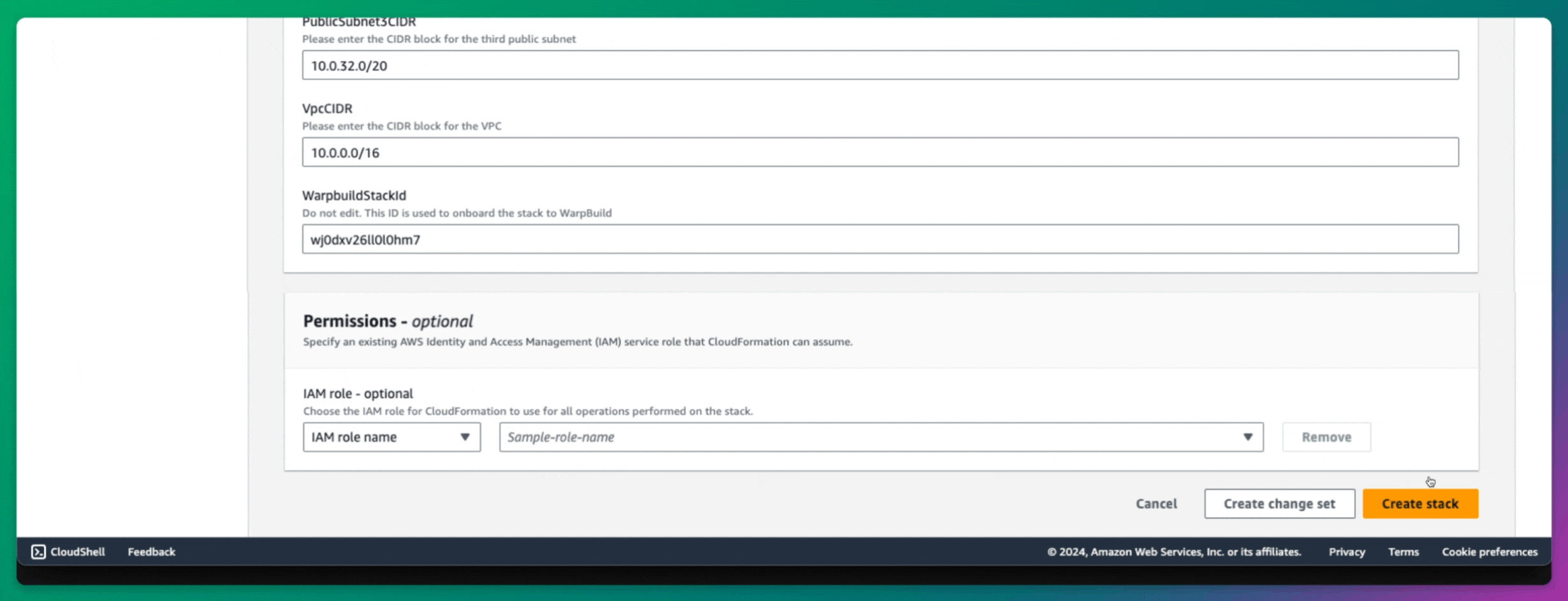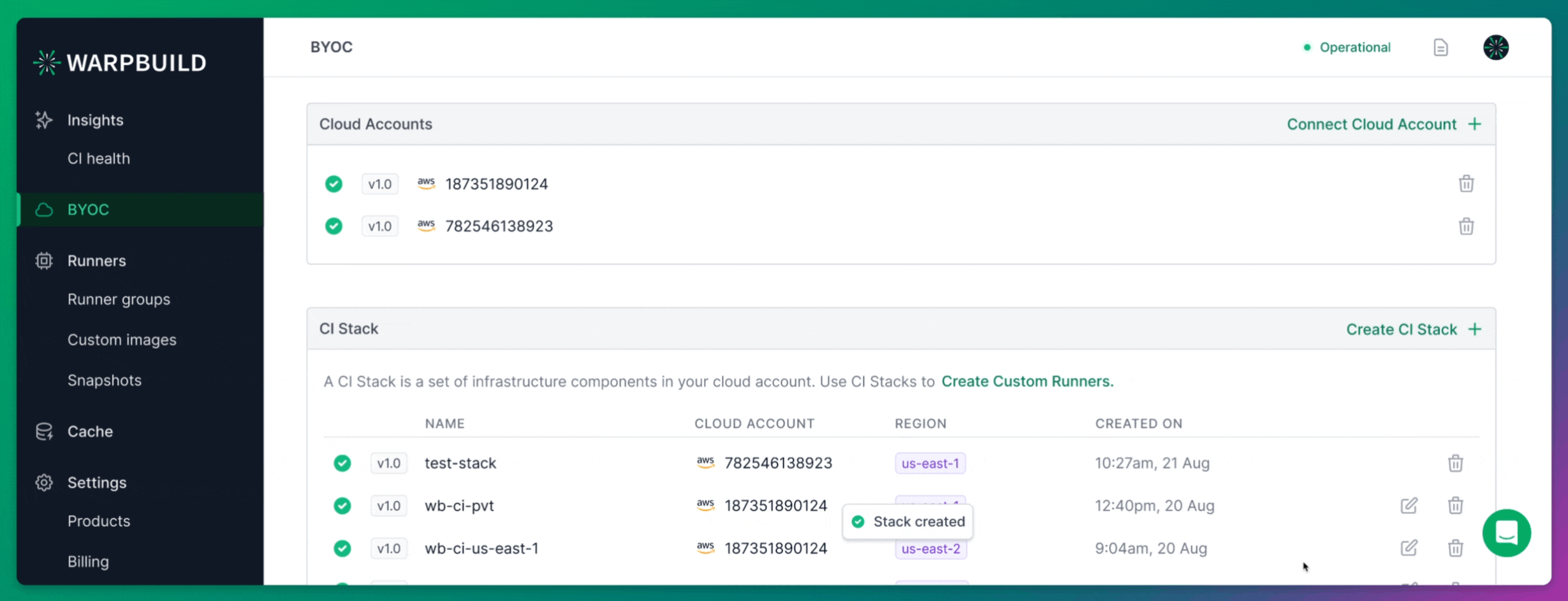
Setting up BYOC Runners on WarpBuild
Adding Cloud Account
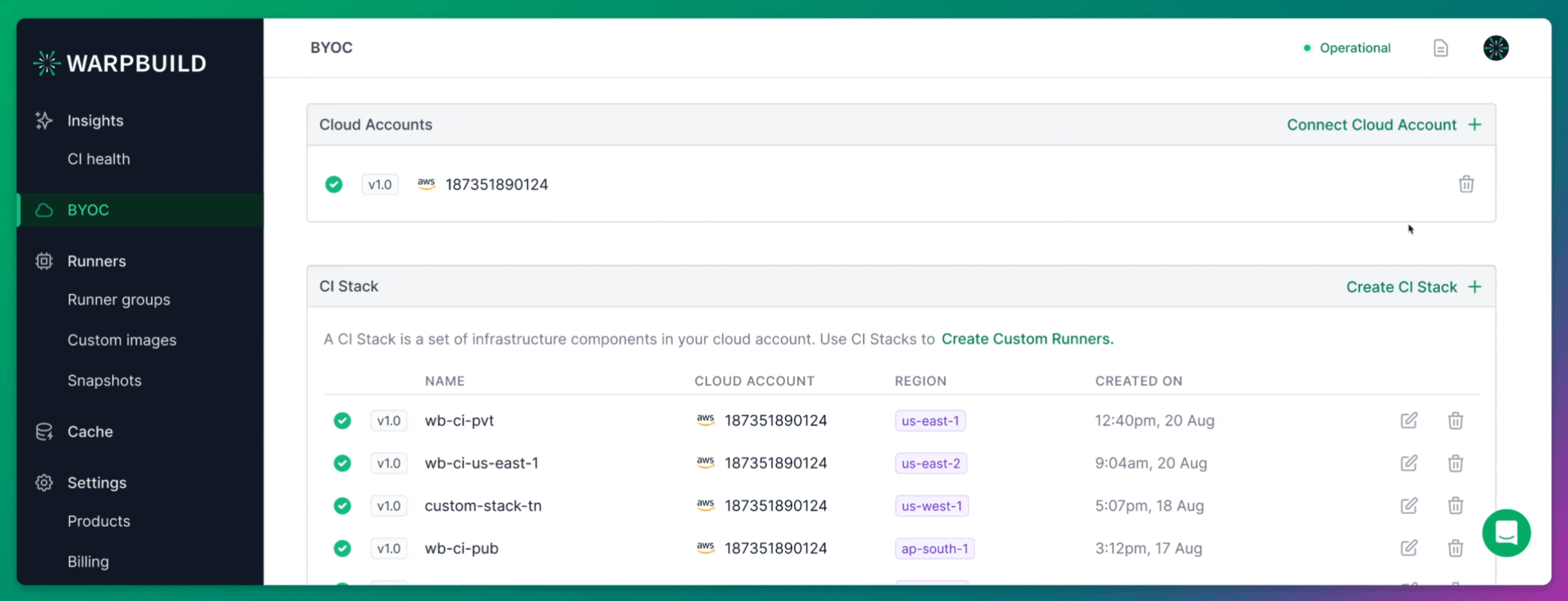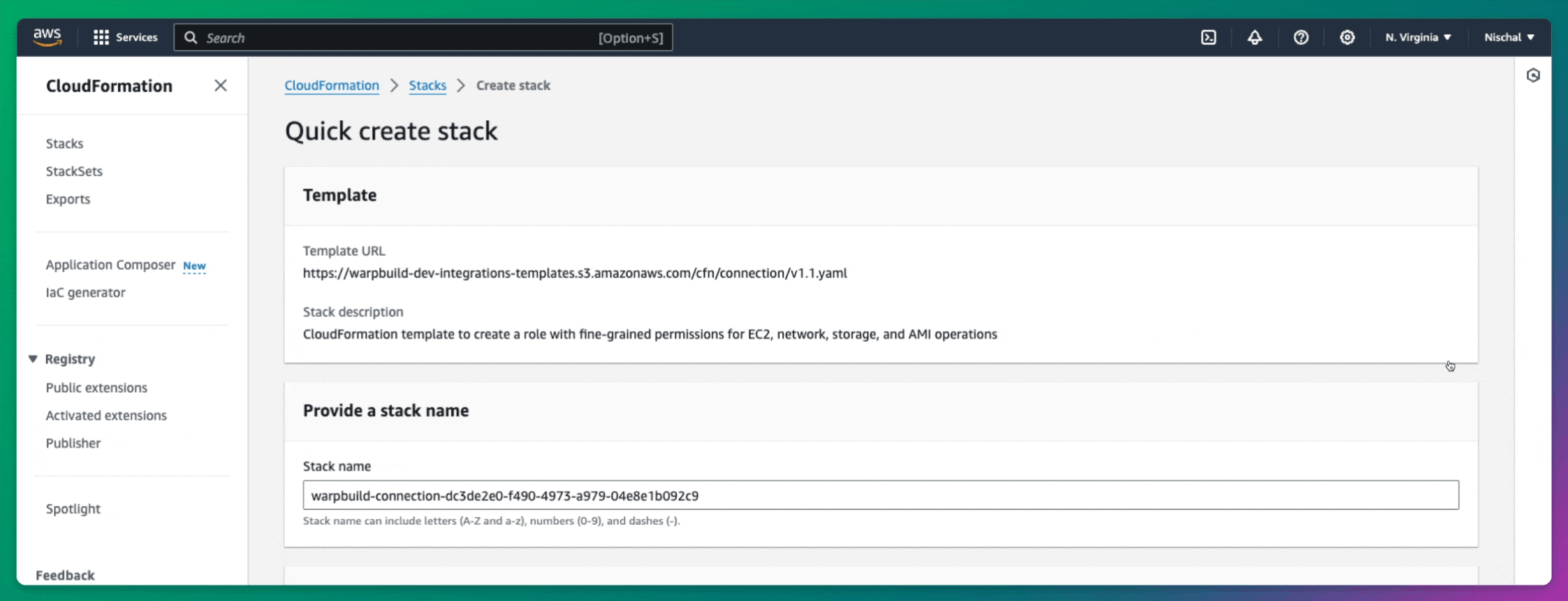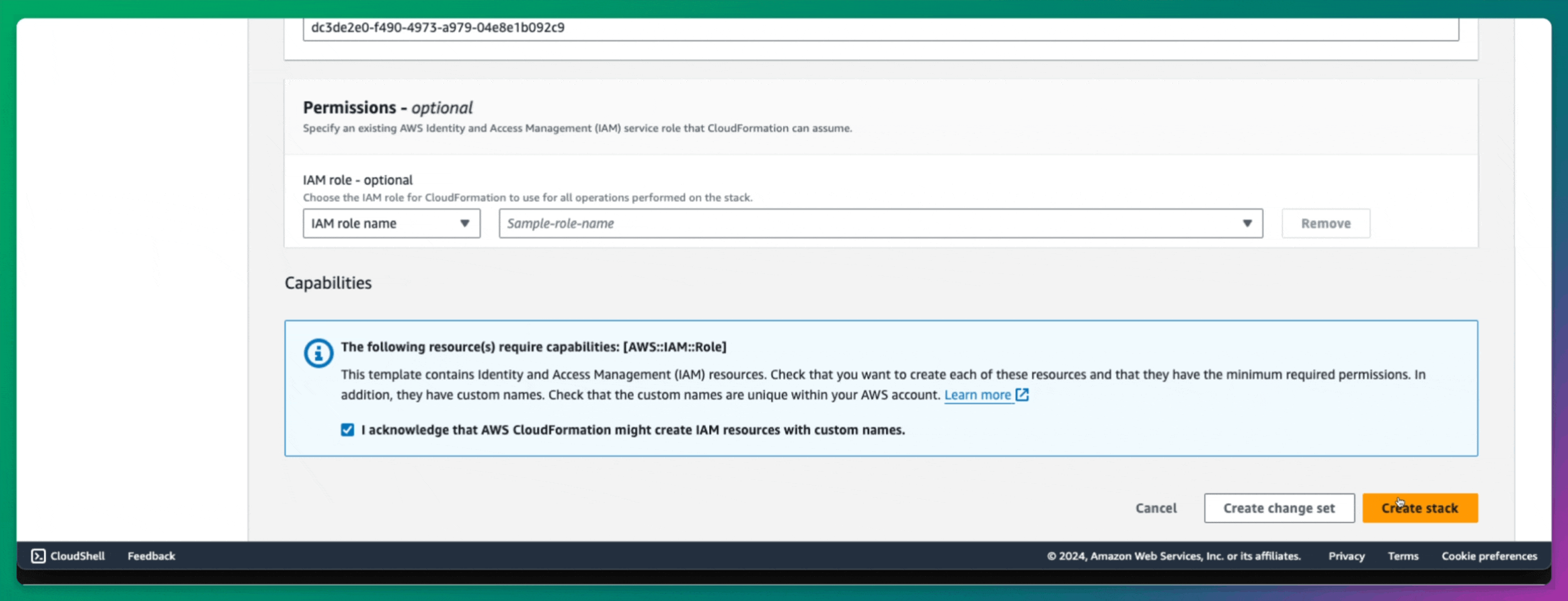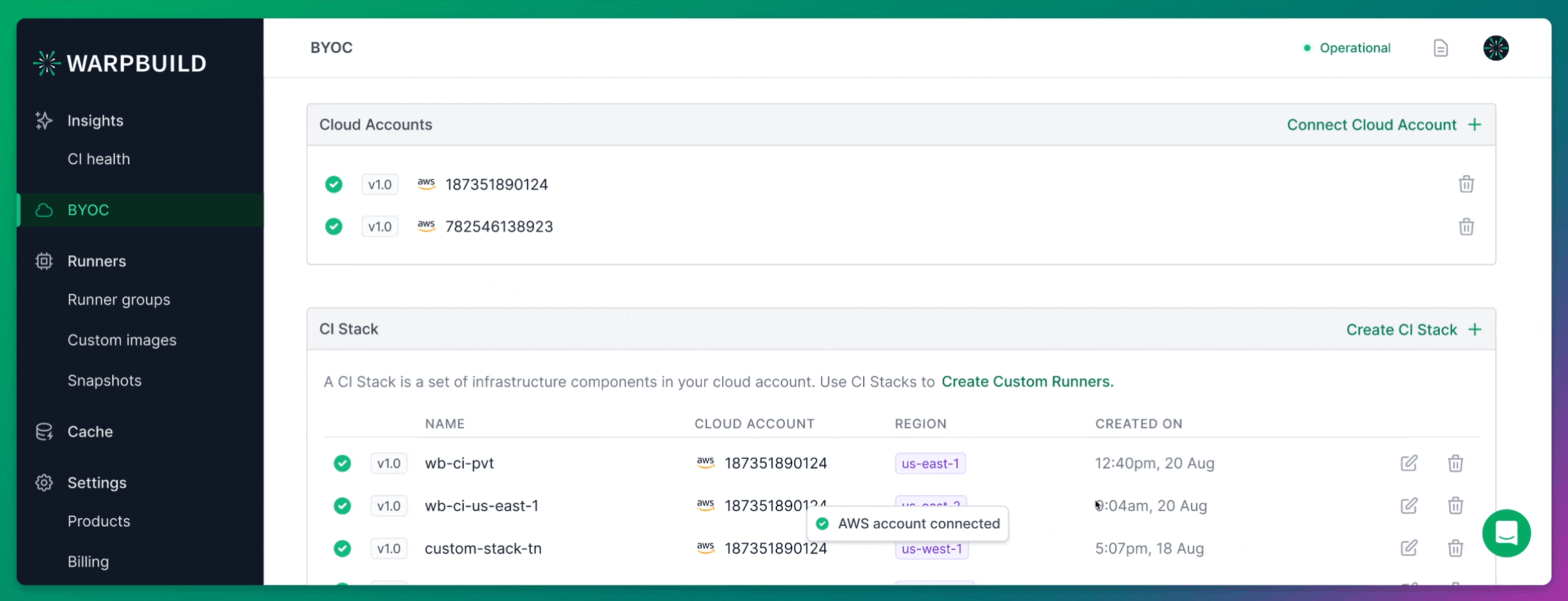
Setting up BYOC (Bring Your Own Cloud) runners on WarpBuild begins by connecting your own cloud account.
After signing up for WarpBuild, navigate to the BYOC page and follow the process to add your cloud account. This step is critical as it allows WarpBuild to provision and manage runners directly in your own AWS environment, providing greater control and flexibility.
Creating Stack
Once your cloud account is connected, you need to create a Stack in the WarpBuild dashboard. A WarpBuild Stack represents a group of essential infrastructure components, such as VPCs, subnets, and object storage buckets, provisioned in a specific region of your cloud account. These components are required for running CI workflows on WarpBuild.
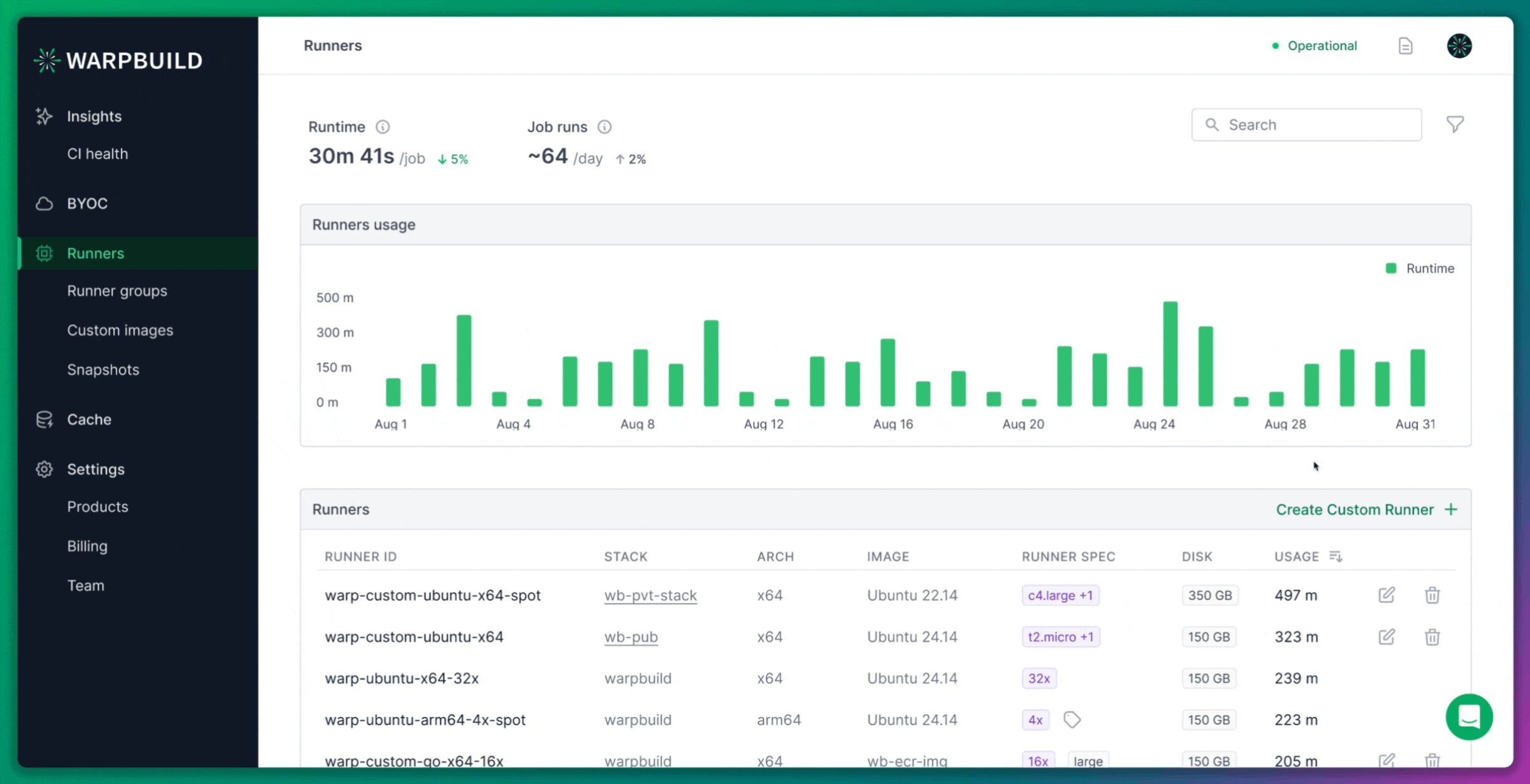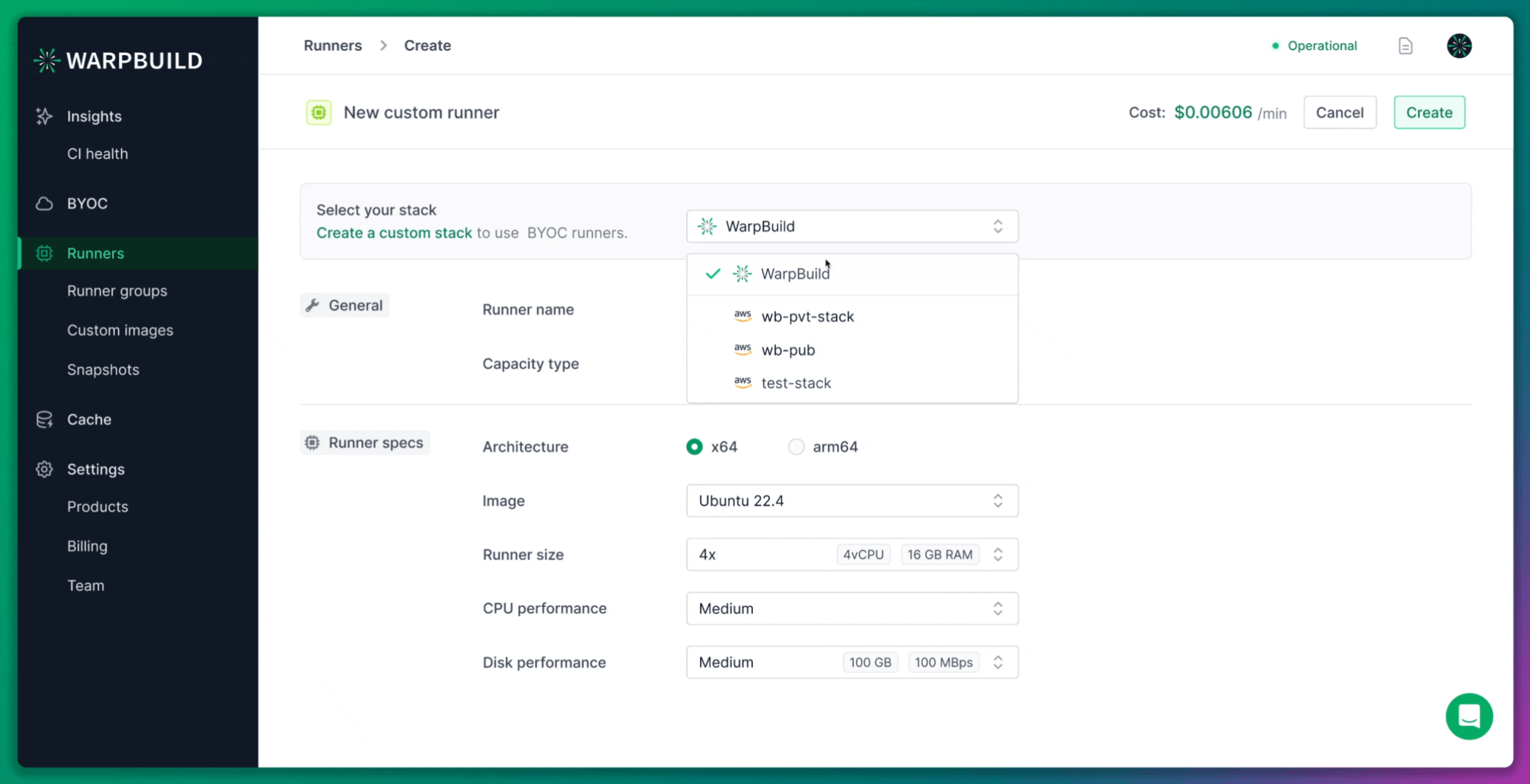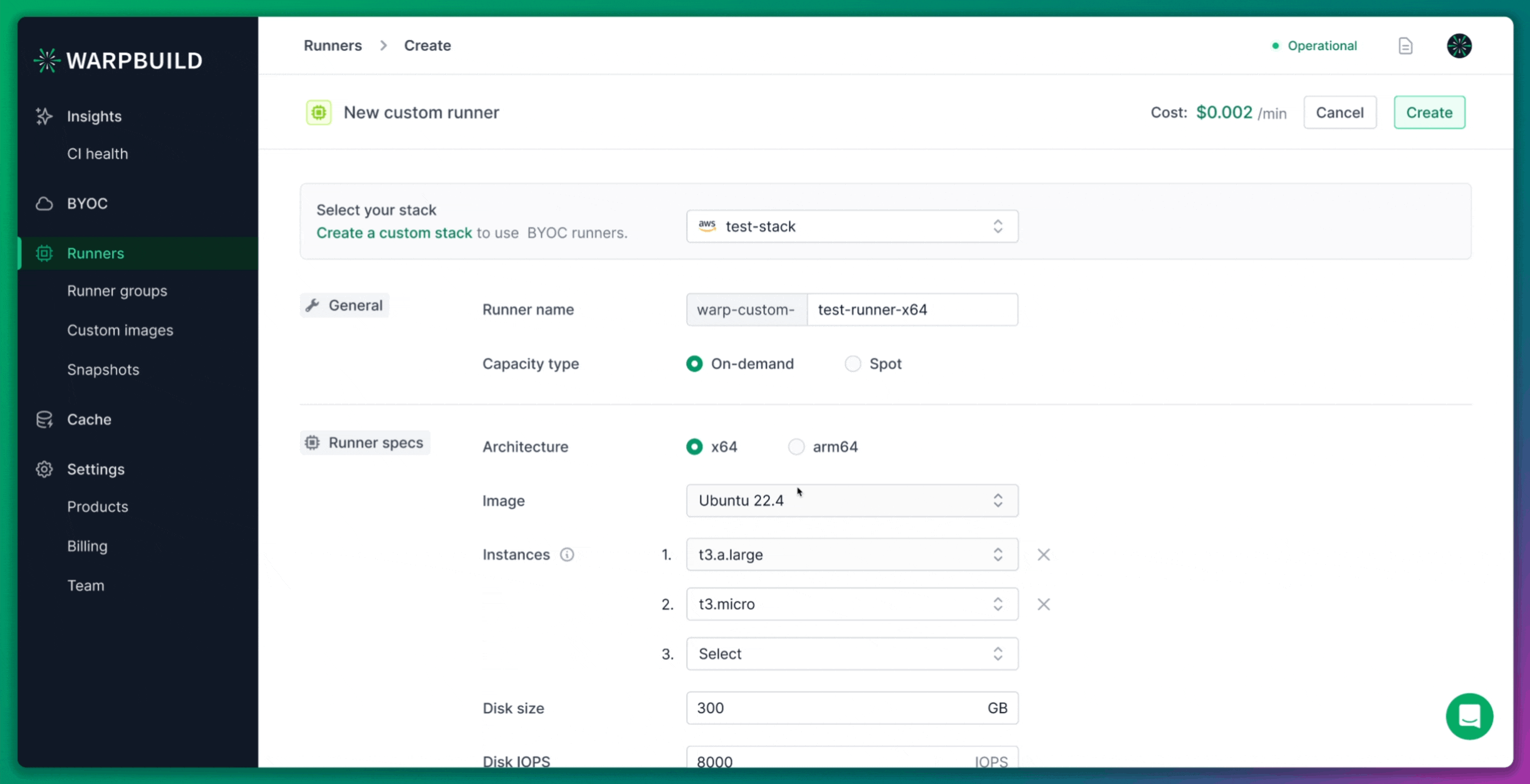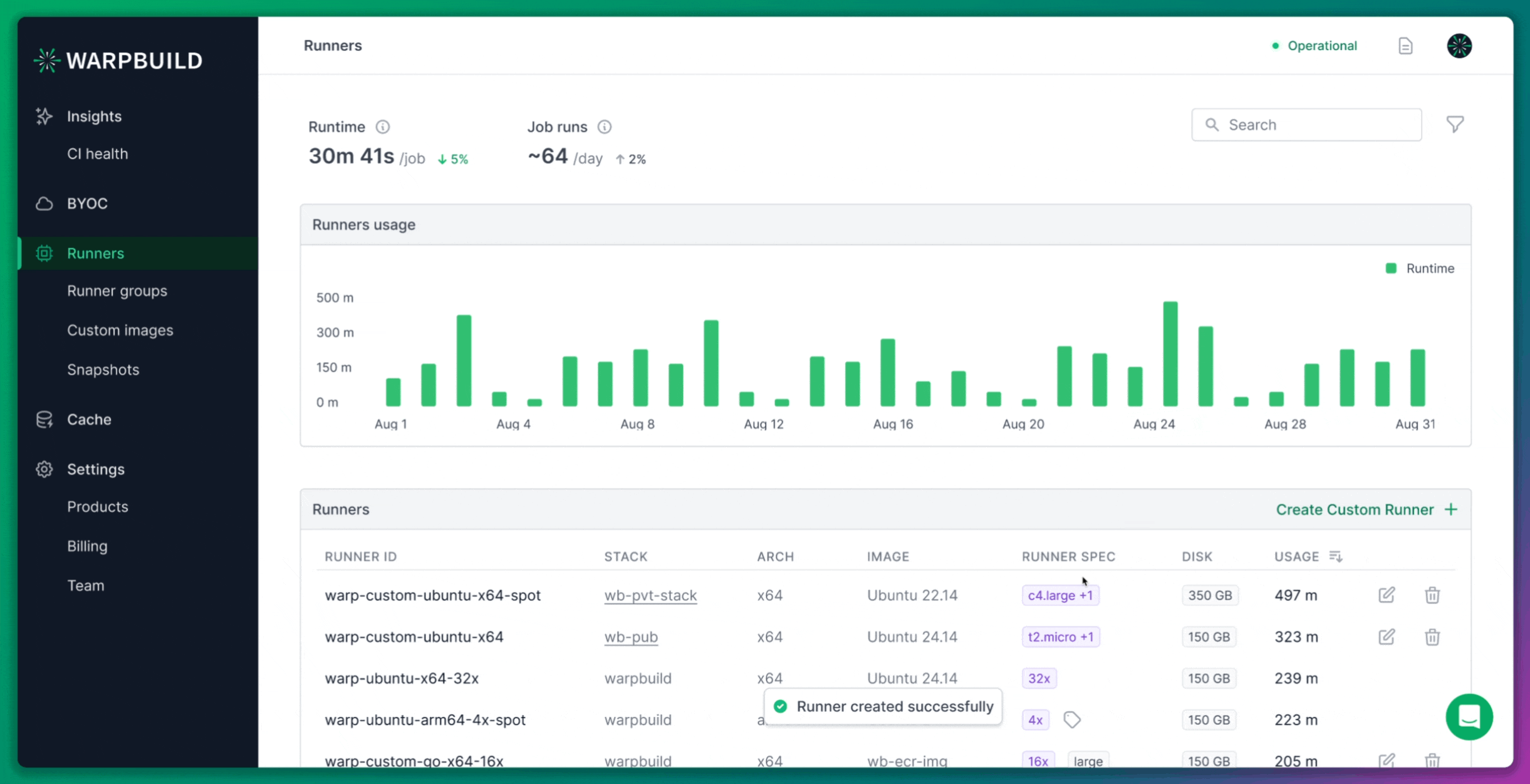
Custom Runner Creation
For this experiment, we also created a custom 8x runner. Although WarpBuild provides default stock runner configurations, creating a custom runner allowed us to match the specifications of the ARC runners.
WarpBuild runners are based on the Ubuntu 22.04 image, which is approximately 60GB in size. This image is pre-configured to work seamlessly with GitHub Actions workflows, offering better performance and compatibility than a general-purpose runner image.
While such an image would be impractical for an ARC setup due to the high storage costs incurred every time a new node is provisioned, WarpBuild manages this efficiently through its runner orchestration.
Tagging Infrastructure for Cost Tracking
WarpBuild simplifies cost tracking for its users by automatically tagging all provisioned resources. This allows users to monitor and manage costs more effectively. Additionally, WarpBuild offers a dedicated dashboard where users can see real-time cost breakdowns, making cost management more transparent.
Workflow Simulation
PostHog's Frontend CI Workflow
To simulate real-world use-case, we leveraged PostHog's Frontend CI workflow. This workflow is designed to run a series of frontend checks, followed by two sets of jobs: one for code quality checks and another for executing a matrix of Jest tests. This setup provided a comprehensive load for both the ARC and WarpBuild BYOC runners, allowing us to assess their performance under typical CI workloads.
You can view the workflow file here: PostHog Frontend CI Workflow
Auto-Commit Simulation Script
To ensure continuous triggering of the Frontend CI workflow, we developed an automated commit script in JavaScript. This script generates commits every minute on the forked PostHog repository, which in turn triggers the CI workflow. Both the ARC and the WarpBuild BYOC runners simultaneously pick up these jobs, enabling us to track costs and performance over time.
The script is designed to run for two hours, ensuring a consistent workload over an extended period for accurate cost measurement. The results were then analyzed to compare the costs of using ARC versus WarpBuild's BYOC runners.
Commit simulation script:
const { exec } = require("child_process");
const fs = require("fs");
const path = require("path");
const repoPath = "arc-setup/posthog";
const frontendDir = path.join(repoPath, "frontend");
const intervalTime = 1 * 60 * 1000; // Every Minute
const maxRunTime = 2 * 60 * 60 * 1000; // 2 hours
const setupGitConfig = () => {
exec('git config user.name "Auto Commit Script"', { cwd: repoPath });
exec('git config user.email "[email protected]"', { cwd: repoPath });
};
const makeCommit = () => {
const logFilePath = path.join(frontendDir, "commit_log.txt");
// Create the frontend directory if it doesn't exist
if (!fs.existsSync(frontendDir)) {
fs.mkdirSync(frontendDir);
}
// Write to commit_log.txt in the frontend directory
fs.appendFileSync(
logFilePath,
`Auto commit in frontend at ${new Date().toISOString()}\n`,
);
// Add, commit, and push changes
exec(`git add ${logFilePath}`, { cwd: repoPath }, (err) => {
if (err) return console.error("Error adding file:", err);
exec(
`git commit -m "Auto commit at ${new Date().toISOString()}"`,
{ cwd: repoPath },
(err) => {
if (err) return console.error("Error committing changes:", err);
exec("git push origin master", { cwd: repoPath }, (err) => {
if (err) return console.error("Error pushing changes:", err);
console.log("Changes pushed successfully");
});
},
);
});
};
setupGitConfig();
const interval = setInterval(makeCommit, intervalTime);
// Stop the script after 2 hours
setTimeout(() => {
clearInterval(interval);
console.log("Script completed after 2 hours");
}, maxRunTime);Cost Comparison
| Category | ARC (Varied Node Sizes) | WarpBuild | ARC (1 Job Per Node) |
|---|---|---|---|
| Total Jobs Ran | 960 | 960 | 960 |
| Node Type | m7a (varied vCPUs) | m7a.2xlarge | m7a.2xlarge |
| Max K8s Nodes | 8 | - | 27 |
| Storage | 300GiB per node | 150GiB per runner | 150GiB per node |
| IOPS | 5000 per node | 5000 per runner | 5000 per node |
| Throughput | 500Mbps per node | 500Mbps per runner | 500Mbps per node |
| Compute | $27.20 | $20.83 | $22.98 |
| EC2-Other | $18.45 | $0.27 | $19.39 |
| VPC | $0.23 | $0.29 | $0.23 |
| S3 | $0.001 | $0.01 | $0.001 |
| WarpBuild Costs | - | $3.80 | - |
| Total Cost | $45.88 | $25.20 | $42.60 |
Performance and Scalability
The following metrics showcase the average time taken by WarpBuild BYOC Runners and ARC Runners for jobs in the Frontend-CI workflow:
| Test | ARC (Varied Node Sizes) | WarpBuild | ARC (1 Job Per Node) |
|---|---|---|---|
| Code Quality Checks | ~9 minutes 30 seconds | ~7 minutes | ~7 minutes |
| Jest Test (FOSS) | ~2 minutes 10 seconds | ~1 minute 30 seconds | ~1 minute 30 seconds |
| Jest Test (EE) | ~1 minute 35 seconds | ~1 minute 25 seconds | ~1 minute 25 seconds |
ARC runners exhibited slower performance primarily because multiple runners shared disk and network resources on the same node, causing bottlenecks despite larger node sizes. In contrast, WarpBuild's dedicated VM runners eliminated this resource contention, allowing jobs to complete faster.
To address these bottlenecks, we tested a 1 Job Per Node configuration with ARC, where each job ran on its own node. This approach significantly improved performance, matching the job times of WarpBuild runners. However, it introduced higher job start delays due to the time required to provision new nodes.
Note: Job start delays are directly influenced by the time needed to provision a new node and pull the container image. Larger image sizes increase pull times, leading to longer delays. If the image size is reduced, additional tools would need to be installed during the action run, increasing the overall workflow run time.
This is a trade-off that you don't have to make with WarpBuild. You can further enhance optimization by leveraging WarpBuild's features custom images, snapshot runners and more.
Conclusion
The cost and performance comparison between ARC and WarpBuild's BYOC offering demonstrates clear advantages to using WarpBuild. WarpBuild provides the same flexibility as ARC in configuring and scaling your own runners, but without the operational complexity and performance bottlenecks (such as resource contention on larger nodes) make it ideal for large-scale workloads. ARC's scalability is limited by node resources like disk I/O and network throughput, which can affect workflow performance despite using high-performance nodes.
WarpBuild simplifies the entire process, offering better performance with lower operational overhead and lower costs. It handles provisioning and scaling seamlessly while maintaining performance, making it the ideal option for CI/CD management for high performance teams.
Last updated on
Your CI Wasn't Built for AI-Assisted Development
Learn why CI pipelines break under AI-assisted development velocity. Discover how to fix queue times, cache thrashing, and flaky tests when using Copilot, Cursor, and other AI coding tools.
Blacksmith vs WarpBuild Comparison - 2025 May
Blacksmith features, performance, pricing, and how it compares to WarpBuild.